1. Confirm evidence exists
A complete corpus artifact usually includespaper.md, metadata.json, evidence_bundle.json, claim_ledger.json, and paper_manifest.json. Do not treat a draft as publishable if evidence or claim-ledger files are missing without an explicit explanation.
Before the artifact writer runs, the control plane should have access to the evidence the worker produced. If paper_evidence_sync_enabled is true, evidence sync runs when you trigger a draft rewrite; you can monitor its outcome in the rewrite response.
When evidence sync is enabled, the control plane attempts an HTTP sync first, reading evidence files directly from the worker-gate API. If the worker returns the evidence, it is written into the local artifact root under the project directory. If the HTTP sync cannot retrieve the required high-signal evidence files, the control plane falls back to SSH, streaming a bounded tarball of evidence artifacts from the worker’s project directory.
Evidence paths the control plane looks for include:
results/ (e.g. hot_cold_sim_results.json, smoke.json) rather than the entire directory. The SSH fallback syncs the entire papers/ directory plus specific result files.
If paper_evidence_sync_enabled is true in your config and no local evidence is found after sync, the rewrite request returns HTTP 424 with an evidence_sync detail object explaining what was tried.
2. Generate Markdown and LaTeX
Once sufficient local evidence is present, the artifact writer runs against the evidence bundle and claim ledger to produce the as-written corpus candidate:papers/<run_id>/paper.md— Markdown draftpapers/<run_id>/paper.tex— LaTeX draftpapers/<run_id>/evidence_bundle.json— Evidence bundlepapers/<run_id>/claim_ledger.json— Claim ledgerpapers/<run_id>/paper_manifest.json— Artifact manifest
paper_writer_* settings. To test Synthetic.new with GLM-5.1, use:
paper_writer_fallback_enabled is true, the writer falls back to a deterministic MVP artifact if the configured provider is unavailable or returns an error. The selected writer output is the generated artifact; Enoch gates it structurally instead of waiting for human prose edits.
3. Scan packaging/provenance checks
After the artifact is written, a publication automation record may still expose legacy fields such asreview_status with values like unreviewed or triage_ready. Treat those as raw compatibility/detail fields, not an operator review queue. The packaging/provenance check includes a ranked checklist of items the automation lane must pass, fail, or accept as a recorded risk before the paper can be finalized. It does not validate peer review, scientific correctness, or independent replication.
The publication automation screenshot below is pending replacement. The current
images/dashboard-paper-reviews.png shows internal paper IDs, score details, and a compatibility-only “Supabase” footer string. Until redacted, treat as layout-only.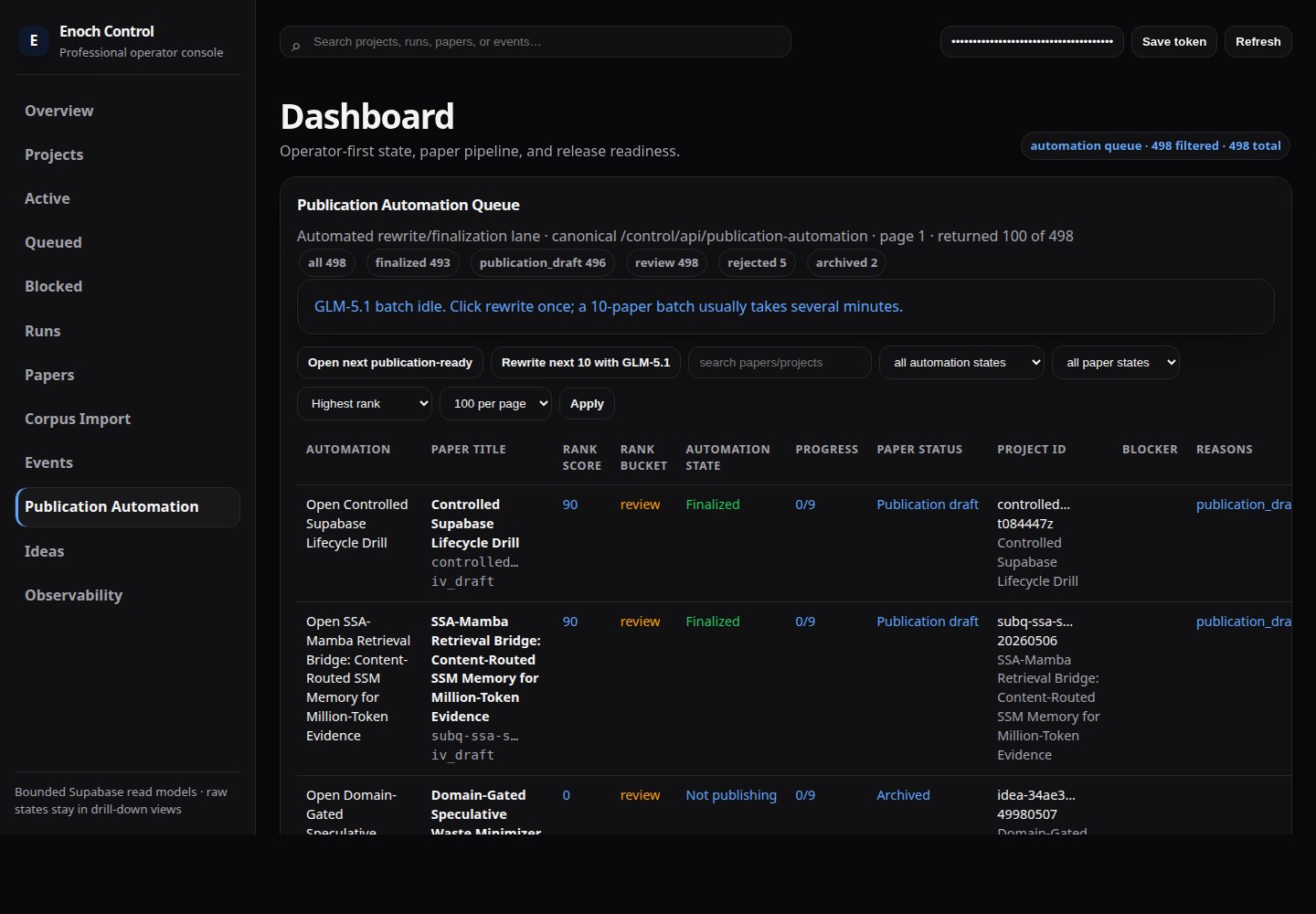
4. Finalize generated drafts
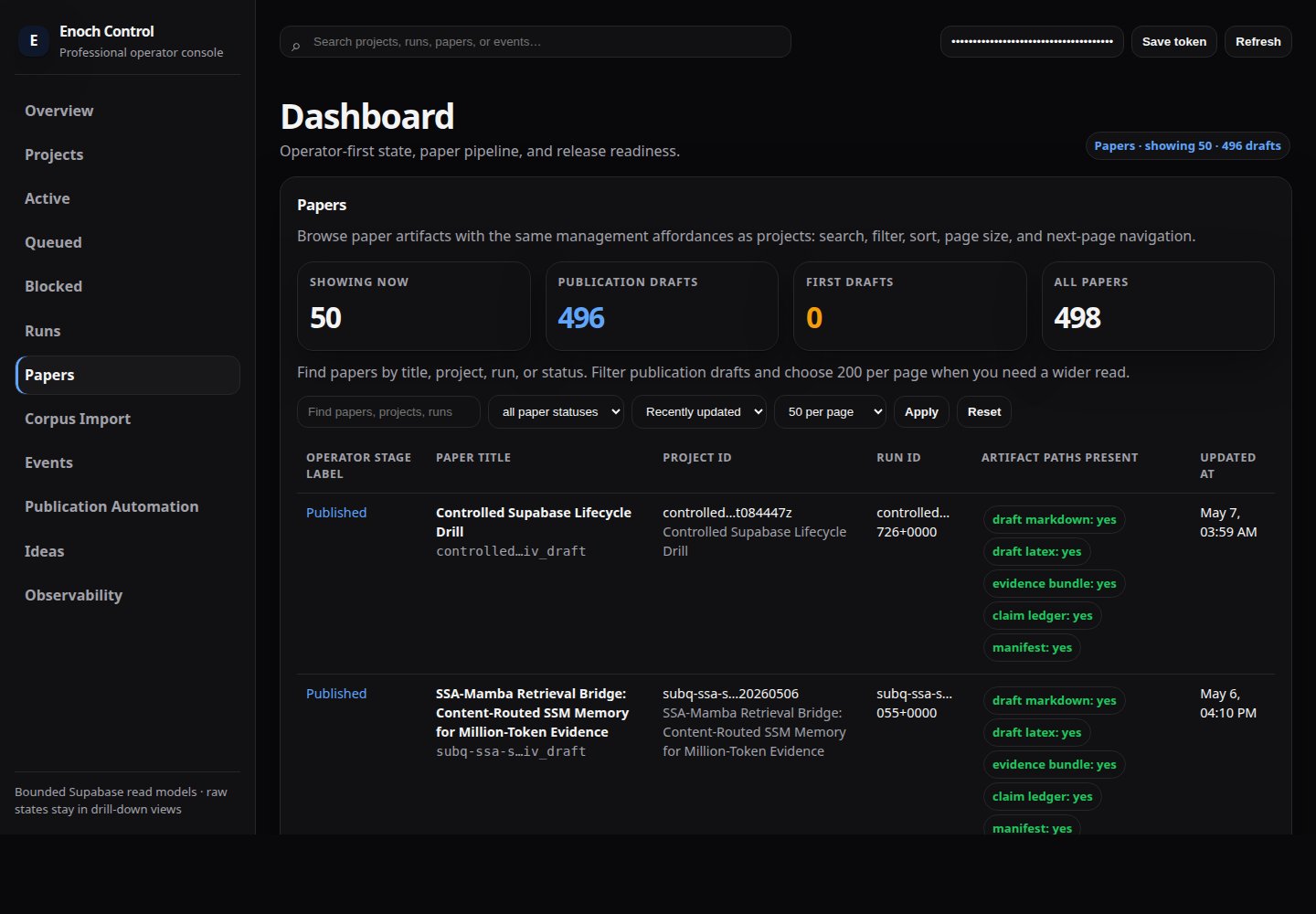
Paper automation APIs support claiming automation items, updating checklist items, changing raw automation state, marking papers ready for finalization, and preparing finalization packages. These are automation mechanics, not a normal human approval workflow. The dashboard presents the simpler operator lanes: write, finalize, publish/import, published/imported, and done/no paper. Generated prose remains AI-generated and not peer-reviewed.The papers queue screenshot below is pending replacement. It currently exposes paper paths and counts that drift over time, and a compatibility-only “Supabase” footer string. Until redacted, treat as layout-only.
5. Rewrite with an optional provider
If configured,synthetic.new can produce the generated artifact through an OpenAI-compatible endpoint. Keep paper_writer_fallback_enabled and deterministic fallback behavior in mind when interpreting output. The result is still pushed as written after gates pass; do not add a separate human rewrite requirement.